.png)

Beyond the Frontier Model: Why Distributed Agents are the New Enterprise Standard
Multi-Agent Systems outperform single models in complex enterprise workflows by decomposing tasks, improving governance, and lowering costs.

The true innovation of an agentic workflow engine lies not in the underlying model but in the robust runtime that surrounds it. As enterprise adoption of task-specific AI agents rapidly accelerates, projected to jump from under 5% in 2025 to 40% by the end of 2026, teams are learning a crucial lesson: the LLM endpoint is only about 15% of the total build. The remaining 85% is the workflow engine itself. This post will systematically break down this engine into its four critical components, detailing the function, composition, and common failure points of each:
The instinct on most early agent projects is to pick a single frontier model and put it everywhere. That works for a demo. In production, it makes the bill look indefensible and the latency look amateur. A serious agent runtime treats the model as a tier, not a constant.
Three tiers show up in almost every production system:
Routing between the tiers is itself a system. Research-grade routers like R2-Router and EvoRoute learn cost-quality tradeoffs from past traces; production teams more commonly run a simpler classifier in front of the call that inspects task type, expected token count, and required tool surface, then picks the tier. The payoff is real: on a moderately complex agent we recently instrumented for a fintech client, replacing a "frontier-only" policy with a three-tier router cut costs per completed task by 58% with no measurable change in success rate.
Two other model-layer decisions matter and get ignored:
Tools are how the agent acts on the world. Confusion in this layer usually traces back to conflating two distinct concerns: how the model expresses what it wants to do and how that intent gets executed.
Those two concerns map cleanly to two technologies:
Tools that mutate state need idempotency keys, and the engine has to thread them through. This is invisible until it isn't.
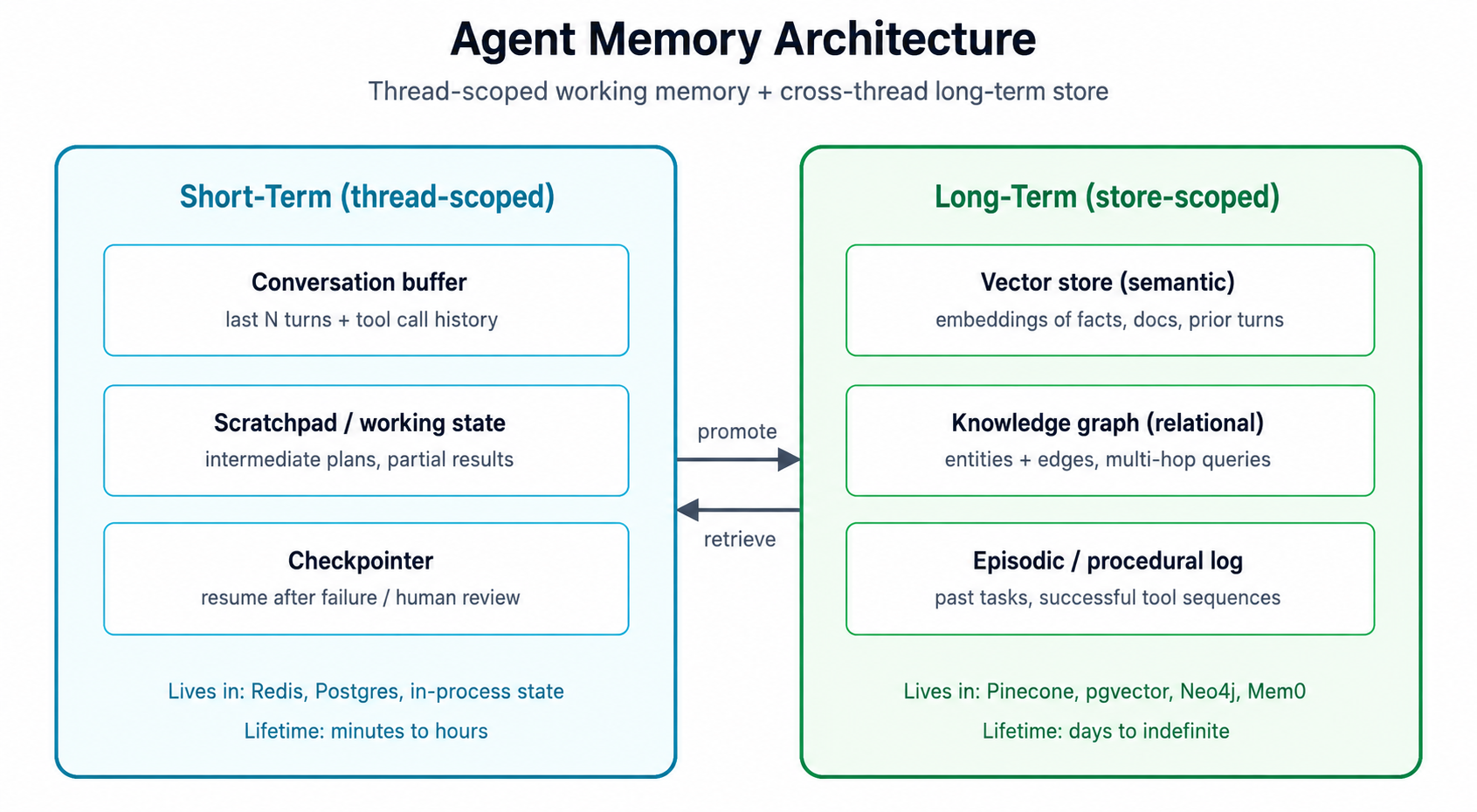
A stateless agent is a fancier chatbot. The moment you ask one to "remember what we decided last week," to "follow up on the deal you opened on Tuesday," or to "use my preferences from the onboarding call," you are in memory territory. The architecture splits cleanly into two regions.
Short-term memory is thread-scoped. It is what the agent holds while a task is in flight:
Short-term memory typically lives in Redis, Postgres, or in-process state and has a lifetime measured in minutes to hours. LangGraph popularized the "checkpointer" term; the pattern matters because long-running agents that cannot resume are a support liability.
Long-term memory is store-scoped. It is what makes the agent useful across sessions. Three substrates dominate in 2026, and each is good at a different retrieval pattern:
The state-of-the-art configuration is hybrid vector plus graph plus episodic because no single substrate handles every retrieval pattern well.
The orchestrator manages the execution flow. Projects often fail due to overbuilt orchestration; start with simple pipelines before moving to complex graphs.
The three patterns, in order of complexity:
Pattern selection correlates strongly with project survival. Gartner forecasts that more than 40% of agentic AI projects will be cancelled by the end of 2027, and the failure pattern is rarely the model. It is an overbuilt orchestration graph of agents launched against problems a linear pipeline would have solved in a tenth of the code, with a tenth of the eval surface.
pipelines. We have successfully deployed products to support our customers.
We specialize in lead generation automation pipelines and have successfully deployed products to support our customers. At Tweeny Technologies, we design and deploy autonomous AI agents that think, reason, and act by researching prospects, drafting proposals, updating CRMs, and executing multi-step workflows. Our systems are built on tool use, persistent memory, and goal-oriented execution, approaching solutions as layered decisions across models, tools, memory, and orchestration for production-grade reliability.
In conclusion, the agentic workflow engine is the result of the seamless composition of its four layers: the model layer for routing, the tool layer for action, the memory layer for persistence, and the orchestrator for flow. While the model provides the reasoning, it is this robust runtime infrastructure that ensures reliability and operational success. Ultimately, the future of agentic AI depends not on the choice of a single model, but on the engine that governs how that model interacts with the world.
The investment shape that follows from this is worth naming. Teams that ship reliable agents do not put 80% of their effort into prompts and 20% into infrastructure. The split is closer to inverted. The model gets the headlines; the runtime gets the renewals.

