.png)

Beyond the Frontier Model: Why Distributed Agents are the New Enterprise Standard
Multi-Agent Systems outperform single models in complex enterprise workflows by decomposing tasks, improving governance, and lowering costs.
In spring 2026, two of the world's most sophisticated tech companies hit the same wall. Uber's CEO admitted the company had "blown through" its entire annual AI budget in three to four months. Microsoft poured a record $37.5 billion into AI in one quarter while barely 3% of its Microsoft 365 customers paid for Copilot. Different symptoms, same disease: tokenomics.
Tokenomics is the economics of how large language models consume tokens, and its signature is a paradox: per-token prices have fallen up to 98% in two years, yet enterprise AI bills have tripled. It is the Jevons paradox: when a resource gets cheaper, people use so much more that total spending climbs anyway. Agentic workflows make it worse, burning 5–30x more tokens per task than a single chatbot call.
You cannot opt out of that curve, but you can control where the tokens go. Dynamic routing is the fix platform teams reach for first: instead of sending every request to your priciest frontier model, an LLM gateway picks the cheapest model that still clears the quality bar. This guide shows the real cost-and-quality numbers behind routing, walks through the new research routers (RouteLLM, EvoRoute, and R2-Router), and gives you a build-vs-buy checklist.
An LLM gateway is a single control plane that sits between your applications and every model you call. Your services make one OpenAI-compatible request, and the gateway handles everything else:
Without it, model selection logic leaks into every microservice, and switching providers means a code change in a dozen places.
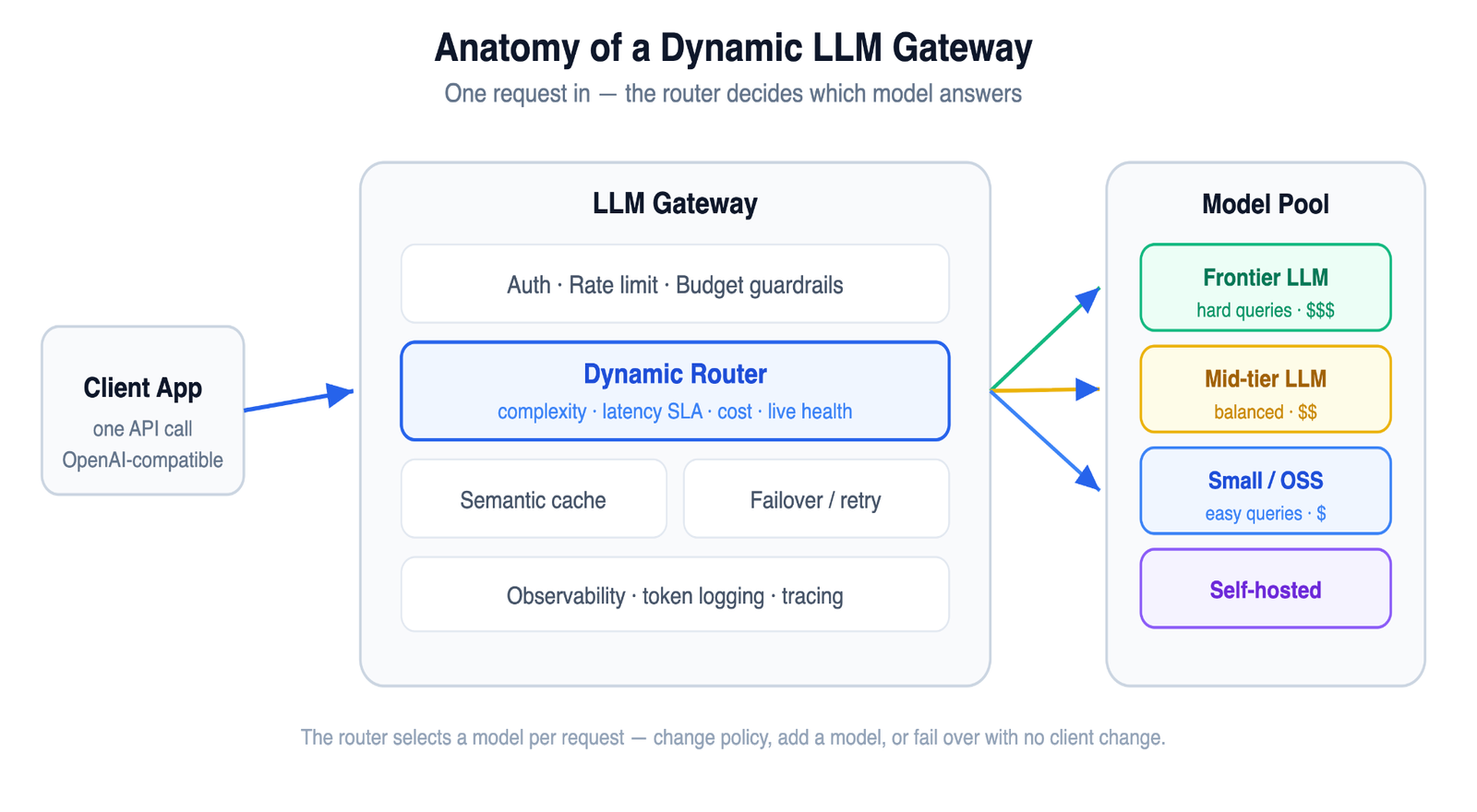
The architectural payoff is decoupling. Your application asks for an answer; the gateway decides which model in the pool delivers it. That indirection is what makes dynamic routing possible at all — you can change routing policy, add a model, or fail over to a backup without touching application code. Performance overhead is small when the gateway is built for it: Bifrost, a Go-based AI gateway, adds only about 11 microseconds per request at a sustained 5,000 requests per second, while Python-based gateways typically add hundreds of microseconds to milliseconds under the same load because of the Global Interpreter Lock. For a routing layer that touches every call, that overhead difference compounds quickly.
Routing works because query difficulty is wildly uneven. Most production traffic is easy classification, extraction, and short answers, and a small, cheap model handles it at near-frontier quality. A minority of requests are genuinely hard and need your best model. Static "always use the best model" policies pay the frontier price for the 80% of traffic that never needed it.
The numbers back this up. RouteLLM, the open-source framework from UC Berkeley's Sky Computing Lab (published at ICLR 2025), shows exactly how uneven the prize is across benchmarks:
Routing savings are real but benchmark-dependent. The harder and more uniform the workload, the smaller the win.
Routing has evolved fast, and the vocabulary matters when you are evaluating tools. There are three broad generations, and most vendors blur the lines between them.
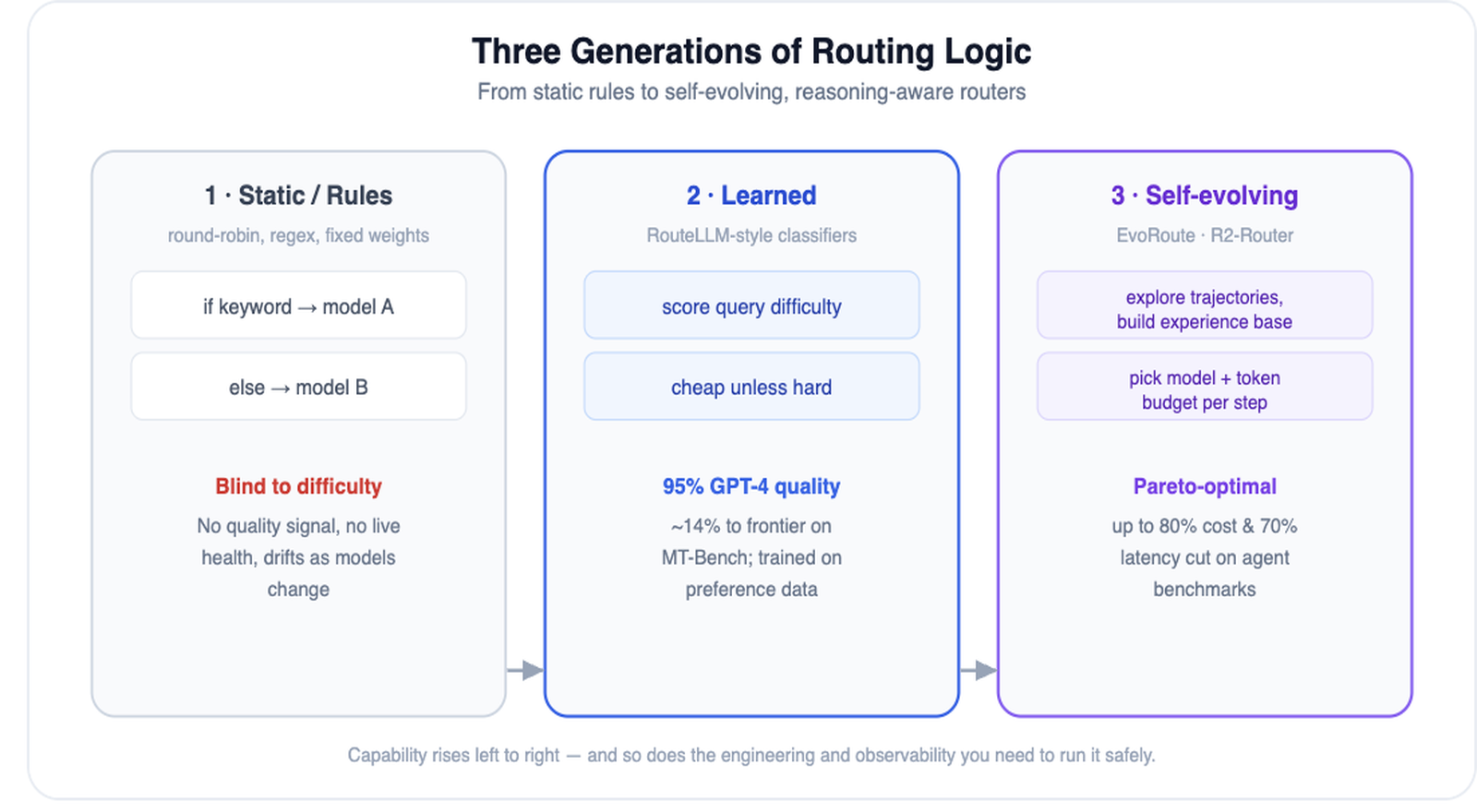
Static routing is rules and weights: round-robin, regex keyword matches, and fixed traffic splits. It is trivial to reason about and blind to difficulty. A static router cannot tell that "summarize this contract" is harder than "what's 2+2," so it either overspends on easy queries or underserves hard ones. It also drifts the moment a provider ships a new model.
Learned routing is the RouteLLM generation: a classifier scores each query's difficulty from preference data and escalates to the frontier model only when needed. This is where most production routing lives in 2026, and it is the realistic starting point for most teams because the trained routers are open source and well documented.
Self-evolving routing is the research frontier, and it is where EvoRoute and R2-Router come in.
Think of EvoRoute as a router that gets smarter the more tasks it runs. It is built for agentic workloads, the multi-step AI work that drove Uber's bill through the roof.
Most routers only choose which model answers. R2-Router adds a second dial: how long the answer is allowed to be.
The practical lesson from both: in 2026, "which model" is no longer the only routing decision. Which model, at what reasoning depth, for which step of the task? That whole surface is now routable, and the savings live in treating it that way.
The two stories from the opening end at the same place, the gateway, the one control point where you can actually govern token spending. Here is what each company is doing about it.
Uber: a spending cap now, the right architecture underneath. Uber's immediate move was blunt — a $1,500-per-engineer monthly soft limit on each AI coding tool after roughly 84% of its developers became agentic coding users and Q1 2026 R&D hit $951 million. A cap stops the bleeding, but it is the emergency brake, not the engine. The more durable answer is the gateway Uber already runs:
That gateway is exactly where a routing-and-budgeting policy belongs, and routing the easy majority of traffic to cheaper models is the structural fix that lets you lift the cap without the bill coming back.
Microsoft: routing sold as a product. Microsoft turned the same cost problem into a managed service. Foundry's Model Router does the routing for you:
The takeaway: Uber and Microsoft are fighting the same force—token consumption outrunning budgets and product payback, and both land on the same architecture described in this guide: one OpenAI-compatible doorway, a routing-and-budgeting brain, and a pool of models behind it.
Ultimately, as LLM inference prices continue their steep decline, the instinct might be to view routing as a transient optimization. The reality is the opposite: the more models and agents proliferate, the more critical the gateway becomes. By abstracting model selection logic and introducing intelligent routing, whether via learned classification or self-evolving frameworks, teams can finally break the cycle of runaway token consumption while maintaining high performance. As demonstrated by the infrastructure strategies at companies like Uber and Microsoft, the LLM gateway is no longer just a luxury for early adopters; it is the essential control plane for any organization that intends to scale its AI initiatives sustainably. In 2026 and beyond, the competitive advantage won't just be about which model you use but how intelligently you route requests across your model ecosystem.